Lecture 12
Location Intelligence /
Recommendation
2026-03-24
Welcome!
This week:
Location Intelligence and Recommendation in urban areas

An example of a marketing campaign using geofencing by Burger King
What is Location Intelligence
Location intelligence is the discipline for turning location data into business outcomes and insights.
Location intelligence goes beyond simple mapping and visualization.
It includes data management, analysis, modeling, prediction, data management, and visualization in an integrative way.
Main industries: retail, real estate, logistics, and transportation.
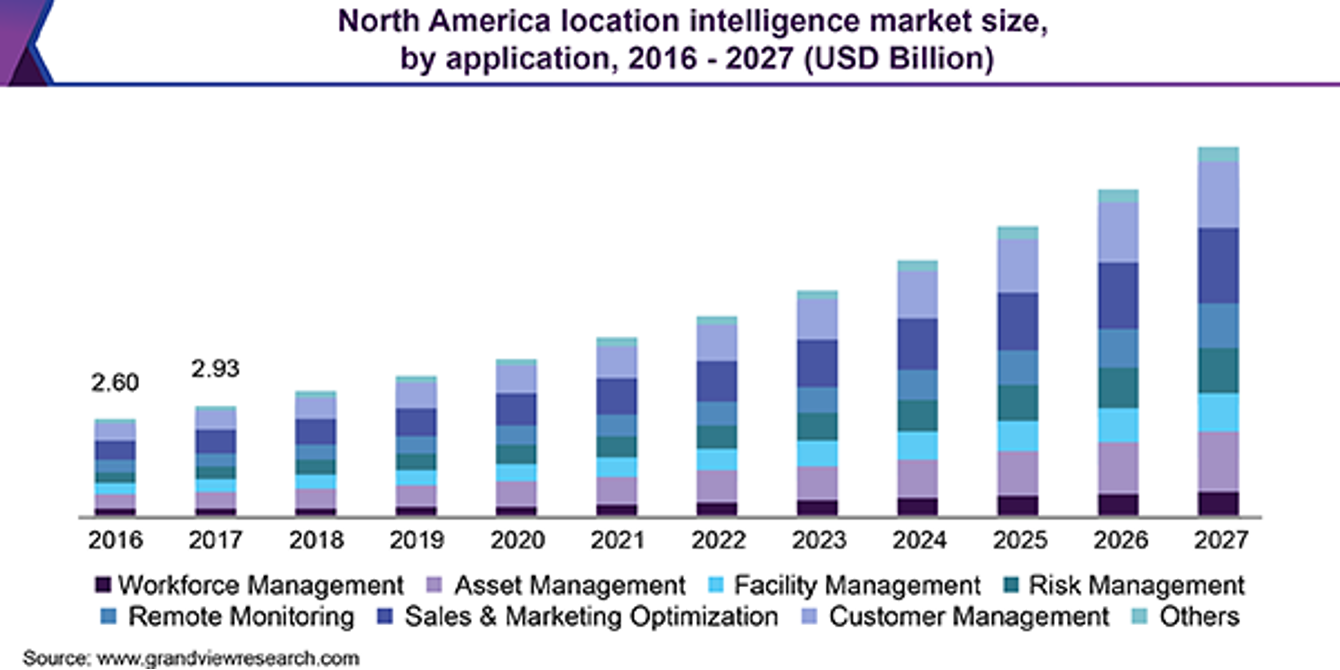
Projections of market size by application in Location Intelligence
What is Location Intelligence
Probably the first example of location intelligence was John Snow’s 1854 study of the spread of cholera. Snow put on a map the cases of cholera and the water pumps. That visualization helped to solve the cholera outbreak.
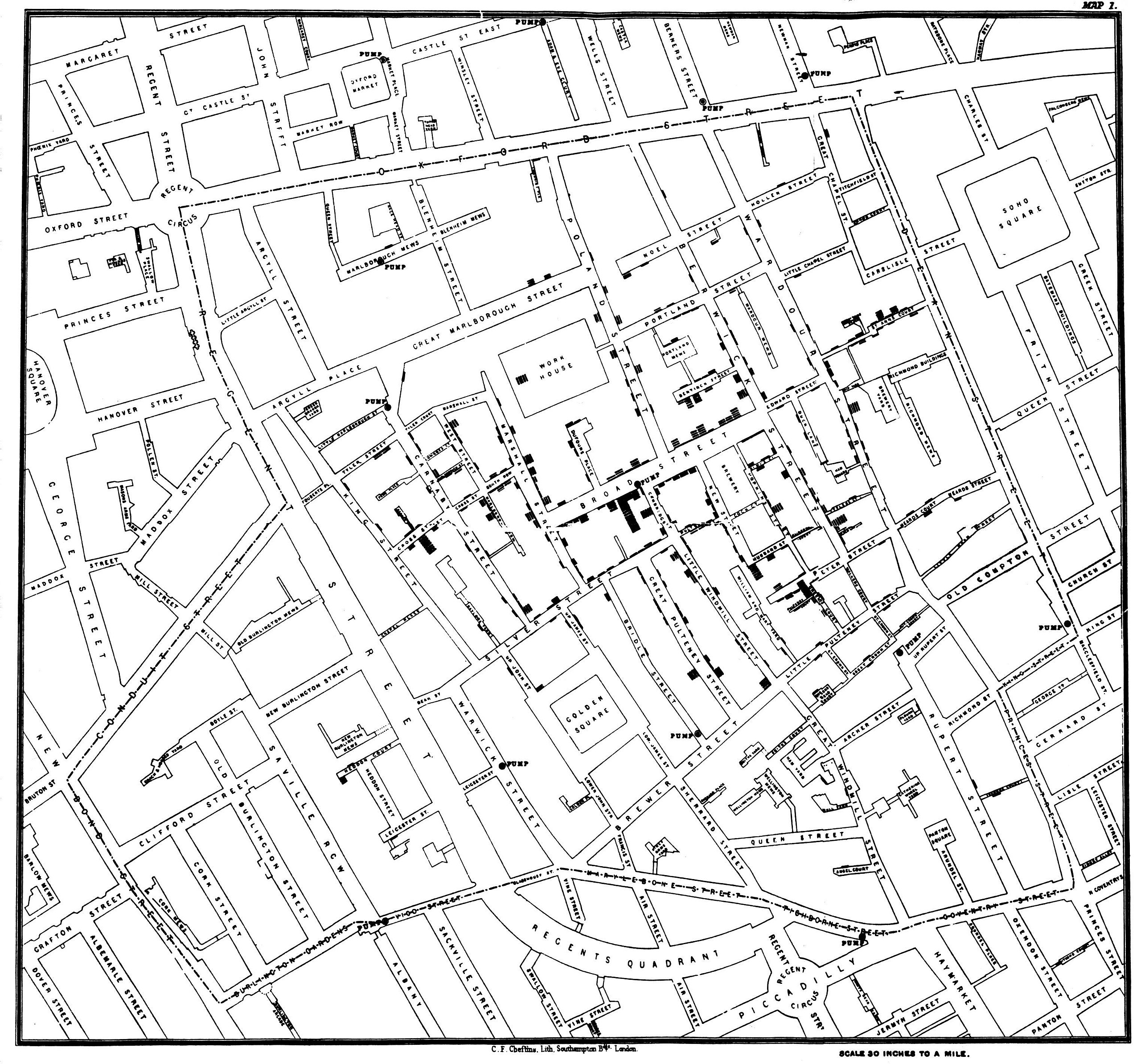
Examples of Location Intelligence
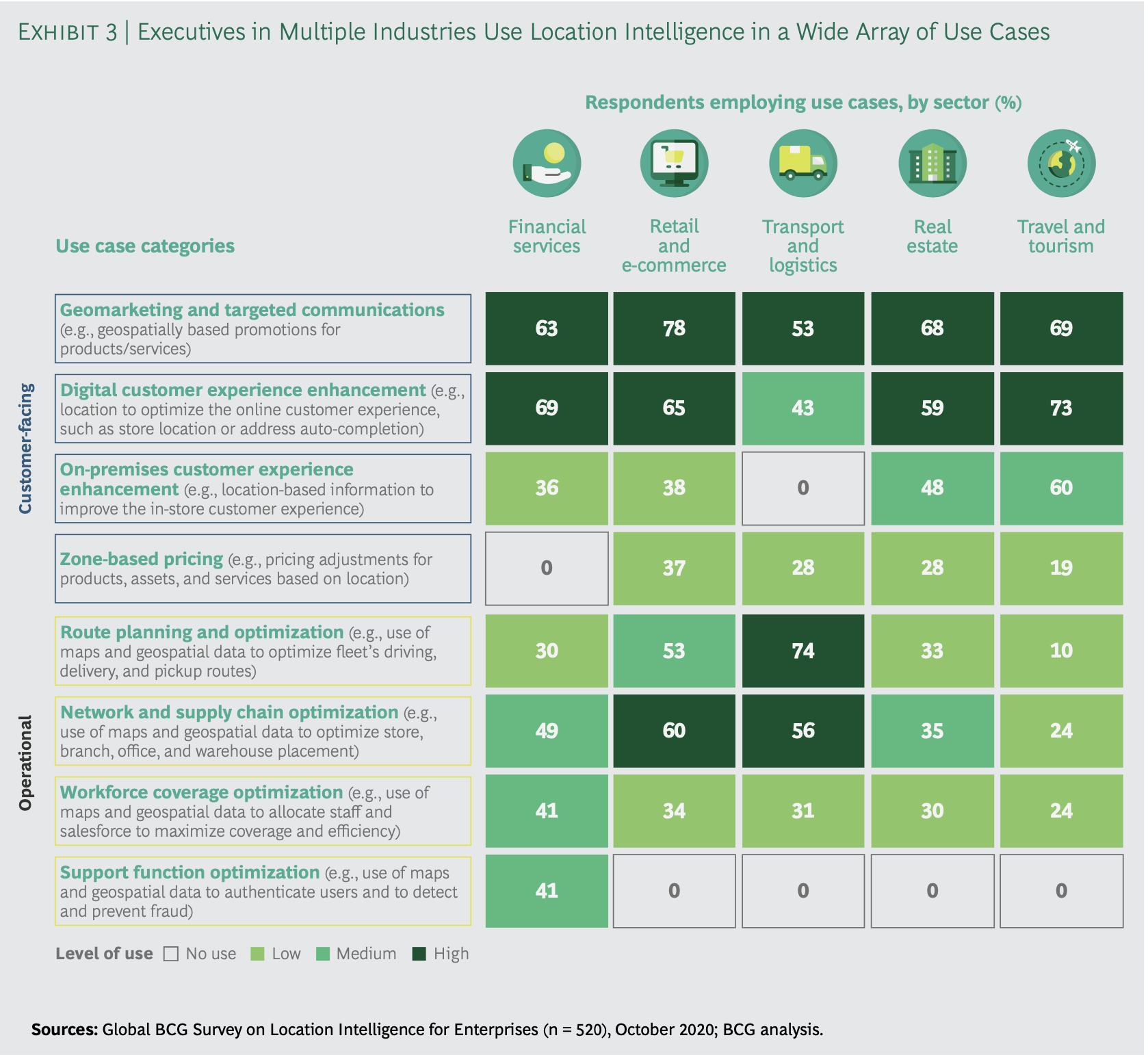
From Google Maps Platform report on LI
Examples of Location Intelligence
- Marketing & Customer Analytics: location intelligence can help retailers understand the demographics of the area, the competition, and the potential customers by using high-resolution location data and advanced models.
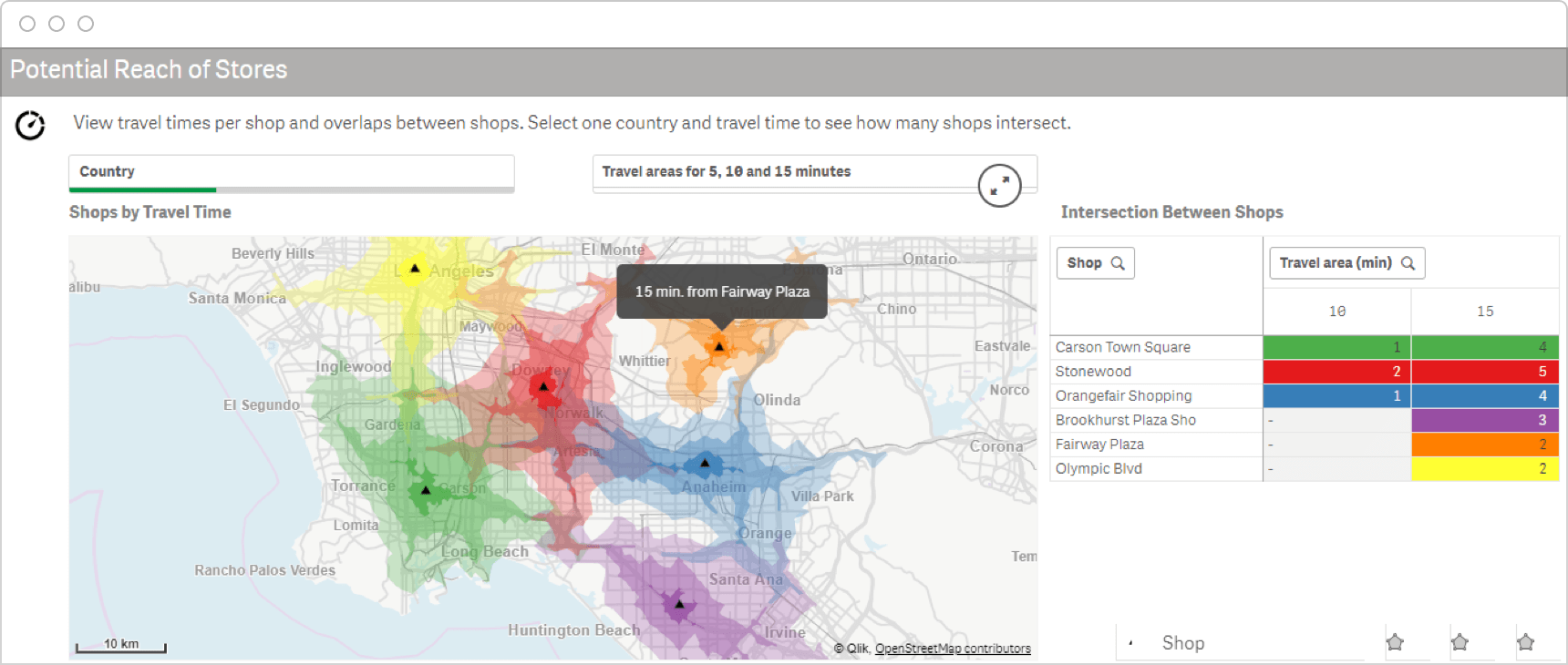
Store Site Selection from Qlik
Examples of Location Intelligence
- Geo-marketing: location intelligence can be used to identify the best locations/people for marketing campaigns, to understand the behavior of the clients, and to optimize the marketing strategies.
An example of a marketing campaign using geofencing by Burger King
Examples of Location Intelligence
- Commercial Estate: location intelligence can help to understand how clients interact with the space, how to optimize the use of the space, and how to improve the experience of the clients.
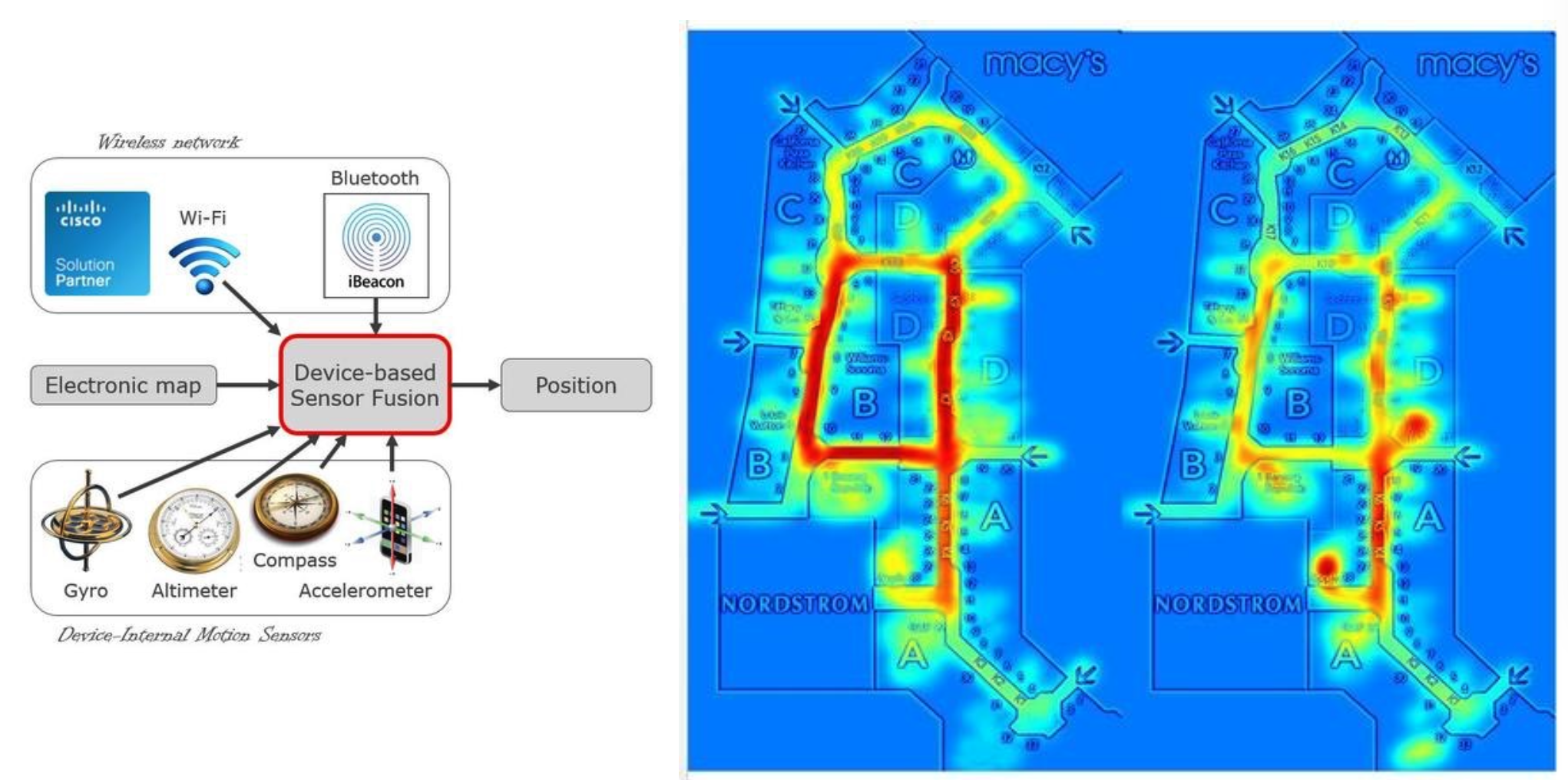
Use of location data in Commercial Estate
Examples of Location Intelligence
- Supply Chain & Logistics: location intelligence can help to optimize the routes, the use of the fleet, and the delivery times.
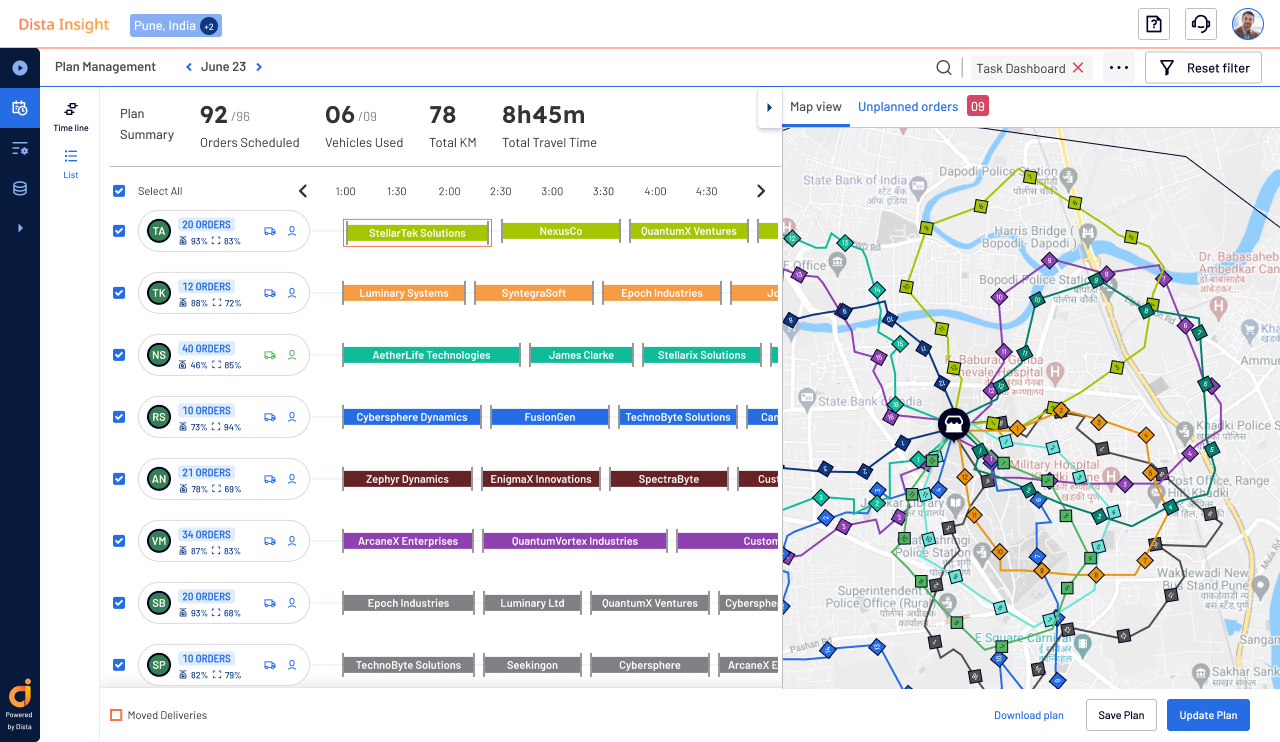
Use of location data in Logistics, from Dista.ai
Examples of Location Intelligence
- Risk Assessment: location intelligence can help to understand the risks associated with locations under flooding, natural risks, etc.
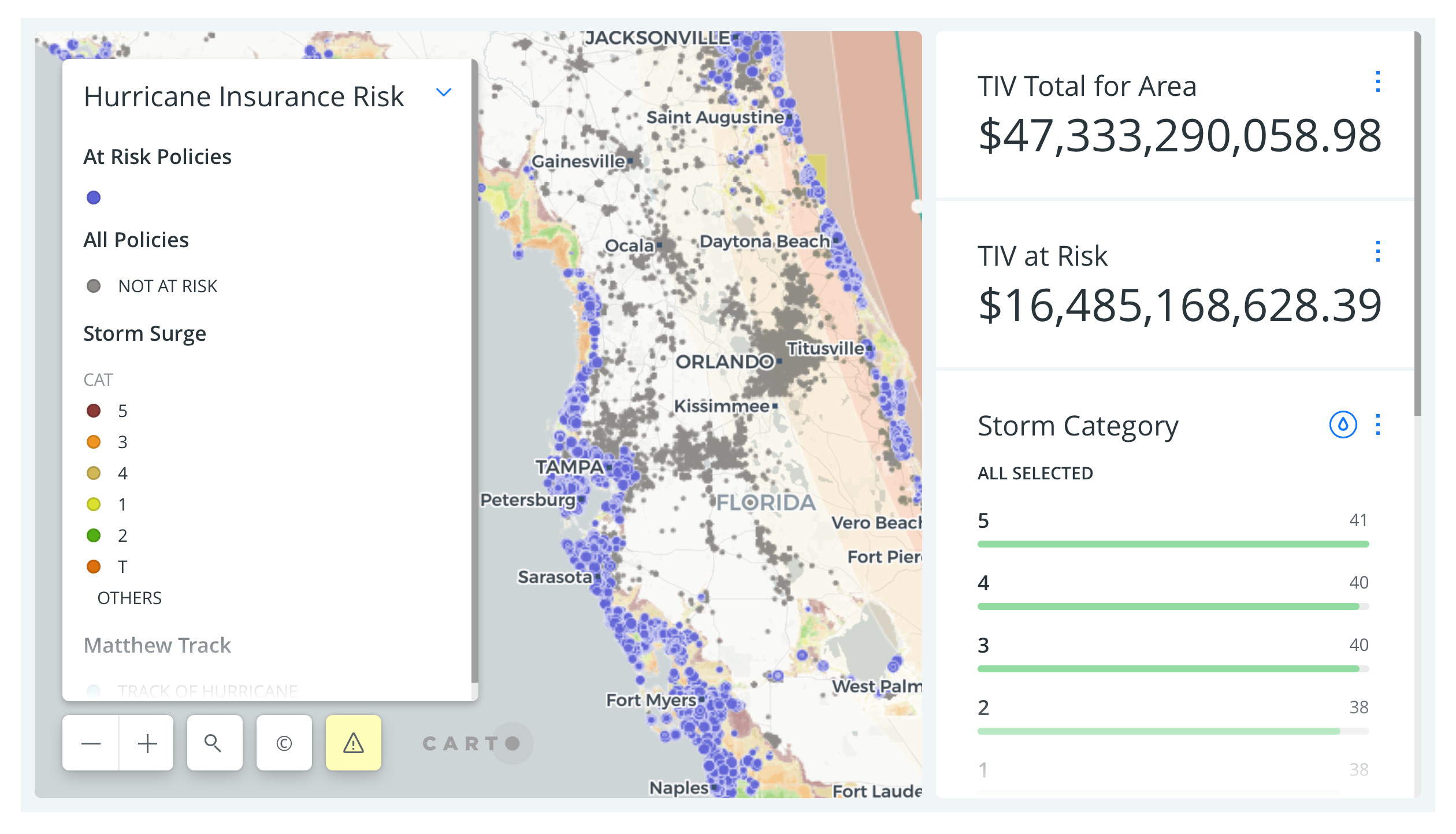
How Insurance Uses Location Data to Prepare for Natural Disasters, by Carto
Examples of Location Intelligence
- Fraud detection: location intelligence can be used to detect fraud by analyzing the location of the transactions, the spatial behavior of the clients, and the patterns of their transactions to detect anomalies
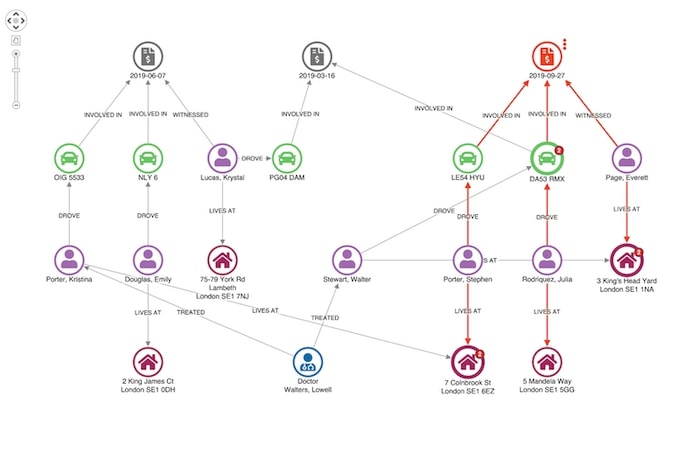
Fraud detection using location data by Cambridge Intelligence
Examples of Location Intelligence
- Urban Policies and Planning: location intelligence can help to understand the behavior of the citizens, the use of the space, and the potential improvements in the city.
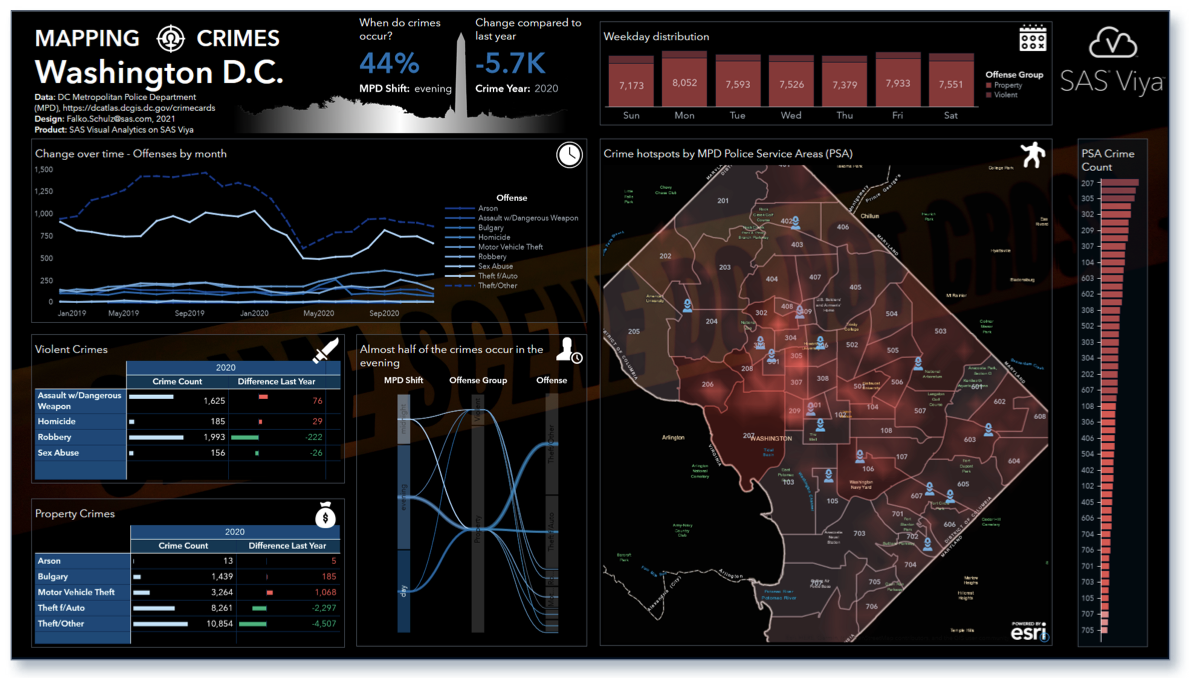
Mapping DC Crimes, by SAS
Sources of data for Location Intelligence
There is a market out there!
Location Intelligence Market, from Geoctrl
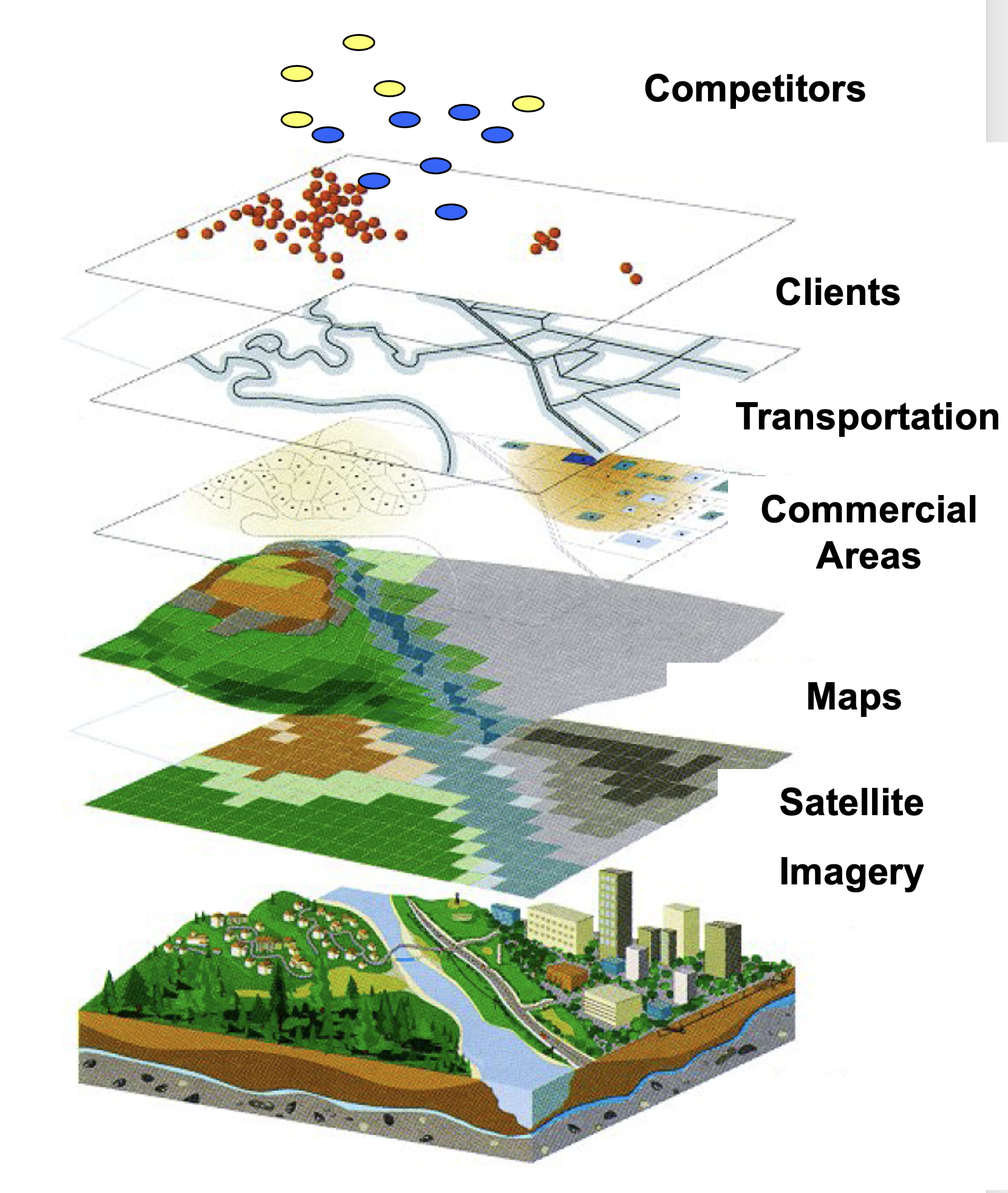
Case study: Location Intelligence in Retail
Data:
- Demographics from the census
- Satellite imagery to understand the land use
- Mobility data from mobile devices or transportation, census
- POIs (Points of Interest) about other businesses and competition
- Sales data from the company
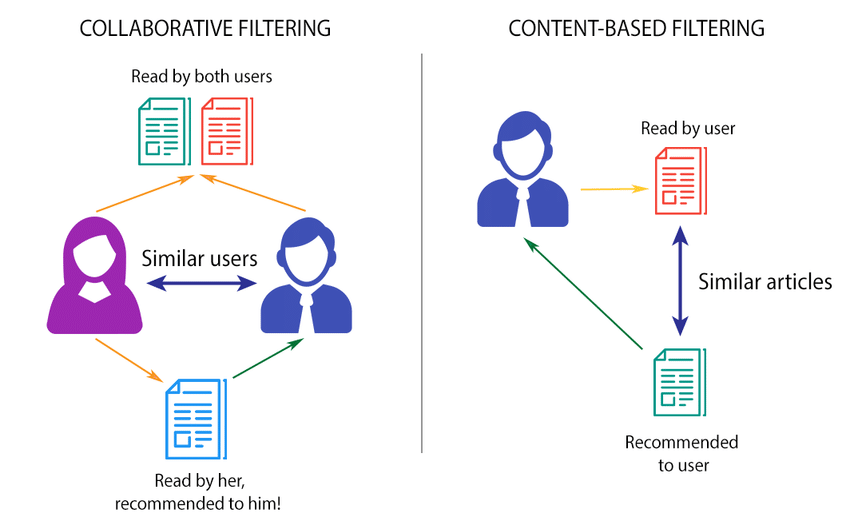
Types of Recommendation Systems
Example: Recommendation of locations
Next place prediction incorporates information about:
- The user’s past behavior (e.g., the places they visited)
- The context where the decision is made (e.g., the time of the day, the day of the week, the weather, the area)
- Information about similar users (e.g., the preferences of similar users, the behavior of similar users)
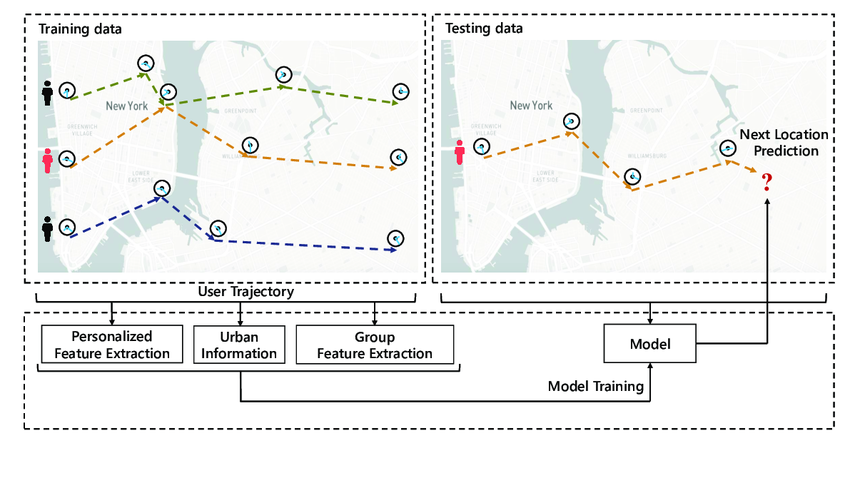
Case study: Recommendation of locations to visit in the city
Then, the recommendation of the next place to visit is
\[ P(\text{next place} = \alpha | \vec u_i) = \frac{u_{i\alpha}^*}{\sum_{\beta=1}^N u_{i\alpha}^*} \]
or choose to recommend only \(\alpha\) according to that probability which are not previously visited only.
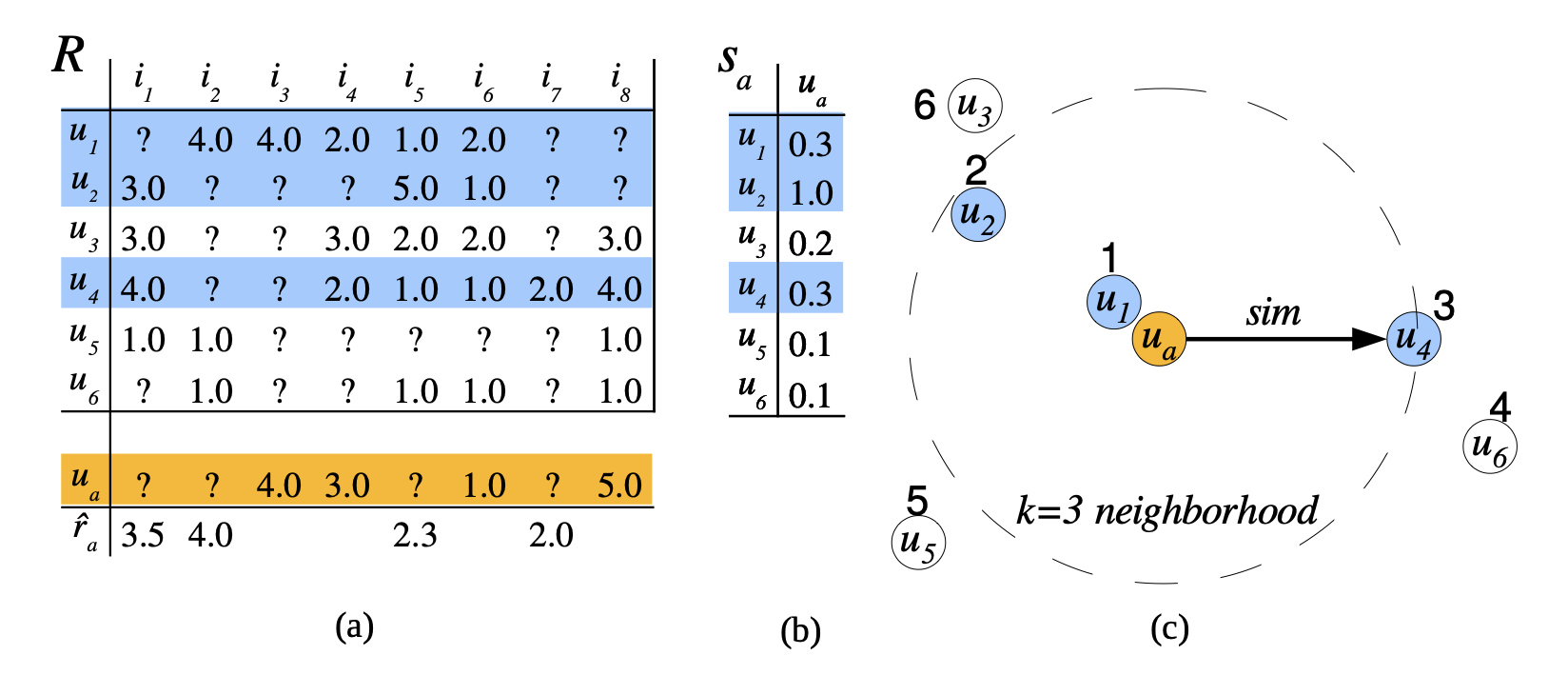
Collaborative filtering algorithm, from [5]
Case study: Recommendation of locations to visit in the city
- Deep Learning: because of the role of repetition, social influence, and context in human mobility, deep learning models based on attention are well suited to predict the next place the user will visit. [8]
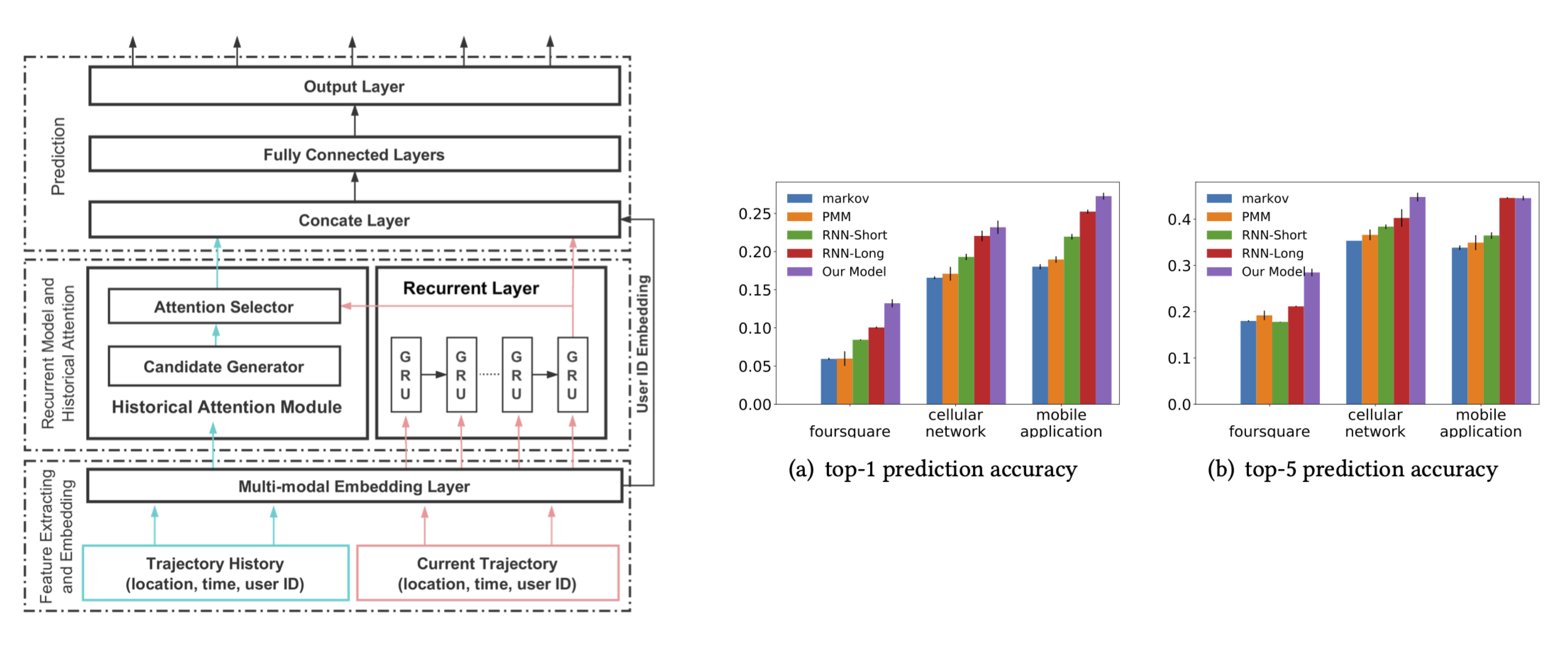
DeepMove model, from [8]
References
![]()